Trust Region Q-Adjoint Matching: Stable Off-Policy RL for Flow Policies
A new stable off-policy fine-tuning algorithm for pretrained flow-based policies, combining trust-region principles with stochastic optimal control.
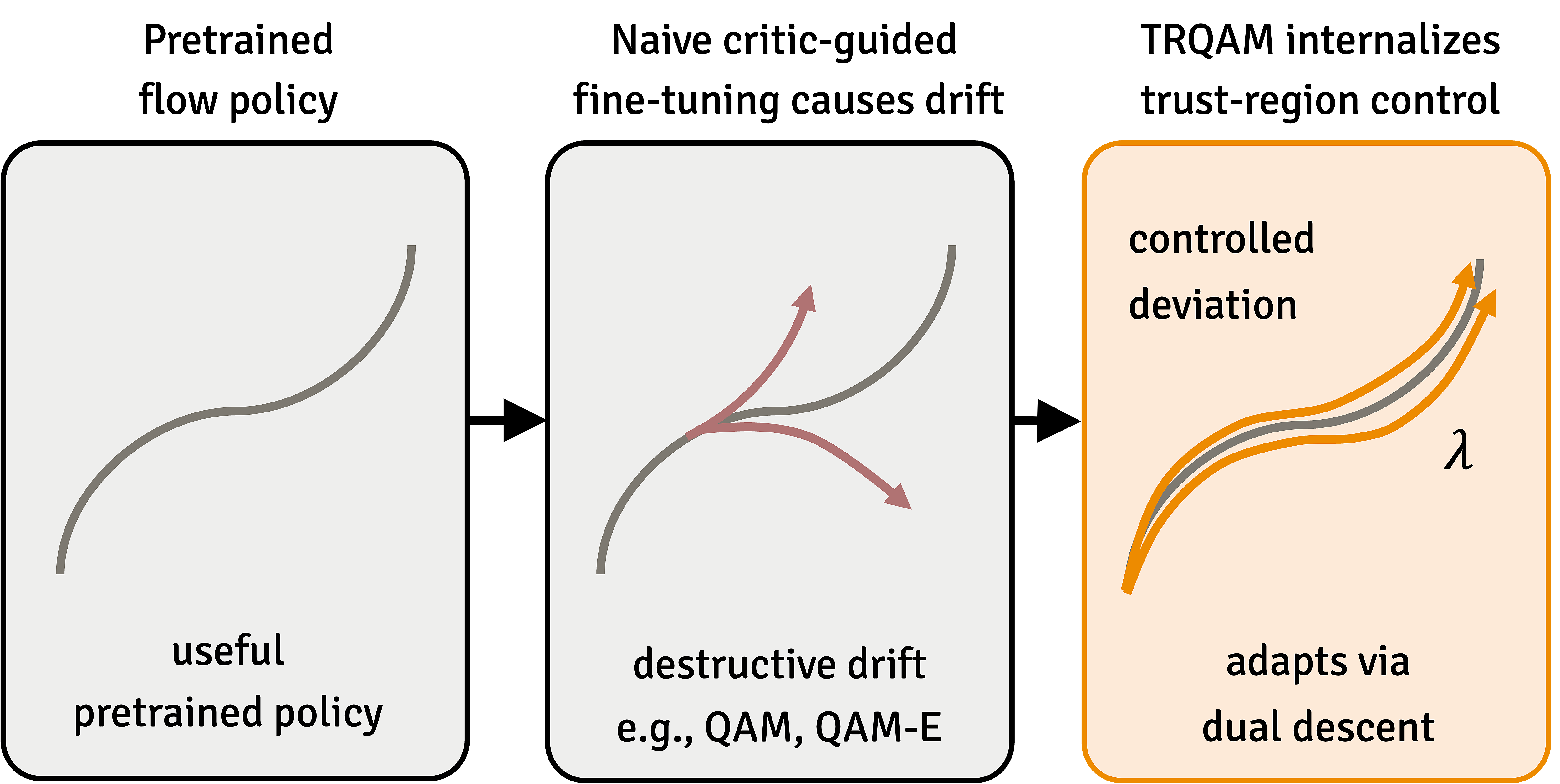
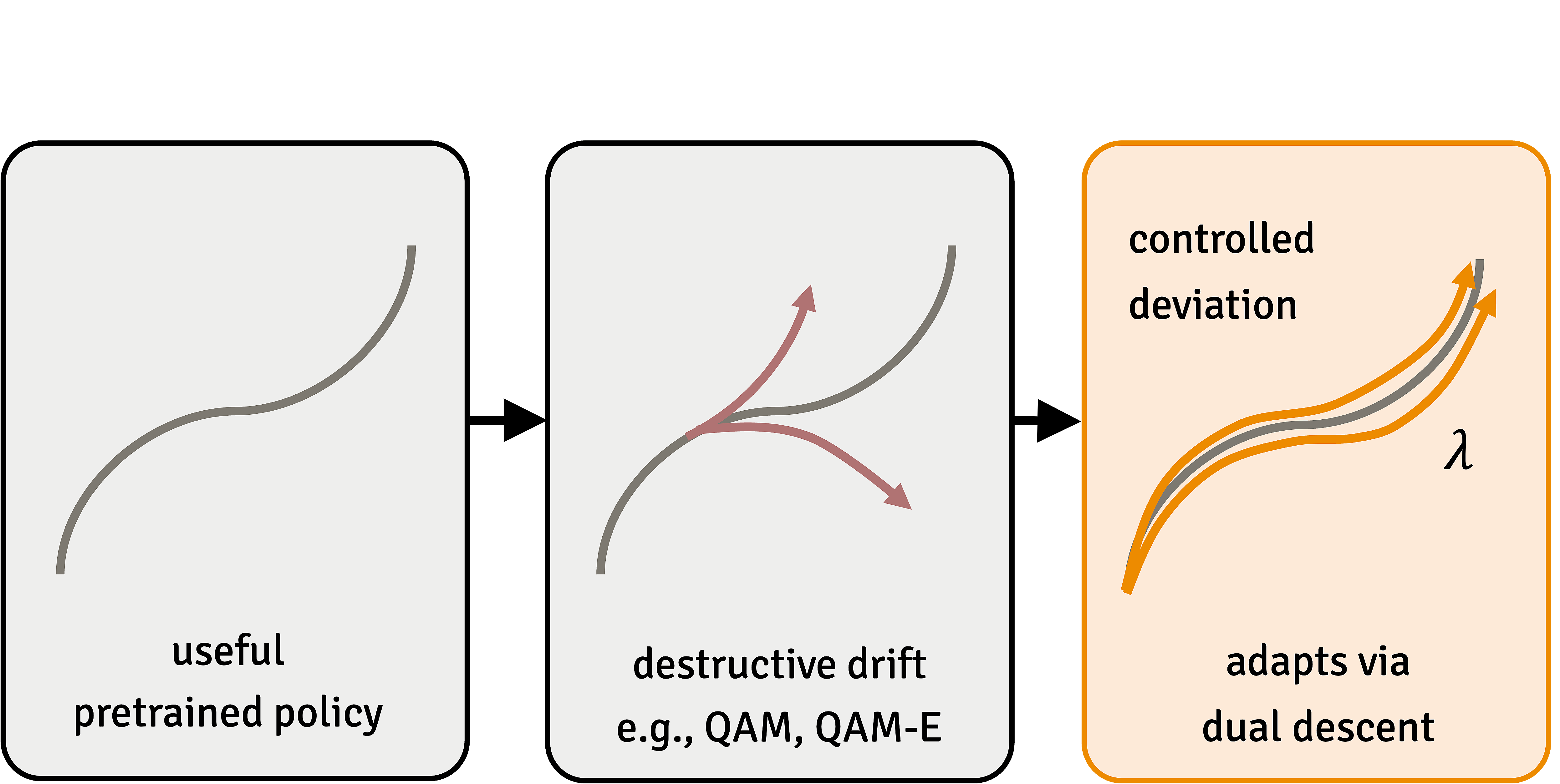
A pretrained flow policy is a useful prior, but naive critic-guided fine-tuning (e.g., QAM, QAM-E) suffers from destructive drift. TRQAM internalizes a trust-region parameter \(\lambda\) inside the sampling dynamics and adapts it via dual descent.
Code: github.com/yonghdong/trqam · Paper: arxiv.org/abs/2605.27079
Large pretrained flow-matching policies have rapidly become the dominant paradigm for robotics foundation models, with a growing family of vision-language-action (VLA) models
The natural next step is to fine-tune them with reinforcement learning: take that pretrained prior and push it further with interaction data on the target task.
On a real robot, that fine-tuning has to be off-policy. Data collection is slow and expensive, every rollout takes wall-clock time, and exploratory actions can be physically dangerous. We cannot afford to throw away transitions after one update, so every transition we collect lives in a replay buffer and gets reused.
Off-policy RL on a flow policy, however, is structurally harder than off-policy RL on a more standard policy (e.g., a Gaussian or deterministic policy). The reason has to do with how a flow policy actually generates its actions.
What makes off-policy RL on flow policies difficult
A flow policy \(\pi_\theta(a \mid s)\) does not predict an action in one shot. It learns a velocity field \(v_\theta(X_\tau, \tau; s)\) that transports Gaussian noise to the action distribution, and samples an action by integrating the resulting ODE:
\[dX_\tau = v_\theta(X_\tau, \tau; s)\, d\tau, \quad X_0 \sim \mathcal{N}(0, I), \quad X_1 \sim \pi_\theta(\cdot \mid s).\]The reason for choosing a flow policy over a simpler parametric family is expressivity: a single Gaussian policy captures only one mode of action, whereas a flow policy captures rich multi-modal distributions
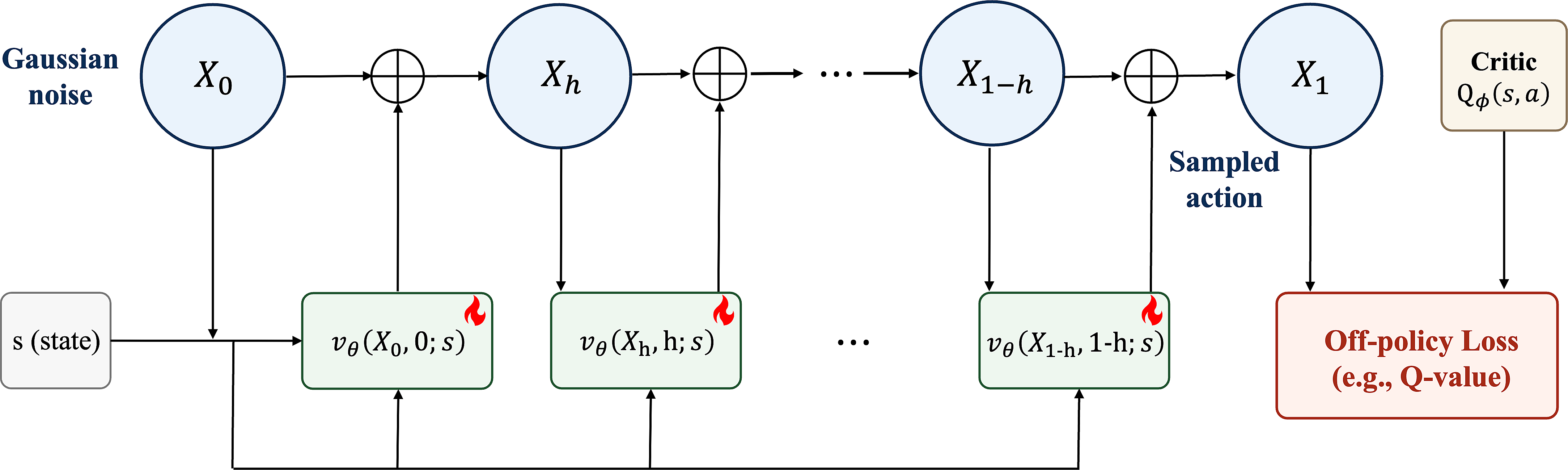
A flow policy produces an action by iteratively applying the velocity network from Gaussian noise. Naive off-policy fine-tuning backpropagates the terminal critic-guided loss through all sampling steps, making optimization prone to instability. (Figure style motivated by SAC Flow
That chain of denoising steps, however, is what makes off-policy RL on a flow policy structurally difficult. The figure above shows why. Modern off-policy RL is essentially Q-learning style actor-critic: train a critic $Q^\pi$ with a temporal-difference (TD) objective, and improve the policy by following $\nabla_\theta Q^\pi$. For a Gaussian policy, that gradient is a single hop from action to parameters. For a flow policy, however, the critic’s signal has to travel all the way back from $X_1$ through every $v_\theta$ block in the figure to reach the policy parameters. This is exactly the same problem as backpropagation-through-time (BPTT) in RNNs
Existing workarounds and their trade-offs
Several strategies have appeared in the flow-policy RL literature to address backpropagation through the sampling chain. Each is principled, and each gives something up.
- One-step distillation (FQL
). Distill the multi-step flow policy into a one-step policy, then run Q-learning on top. - Pro: removes the chain entirely; the resulting one-step policy is directly trainable with standard off-policy actor-critic.
- Con: the one-step policy has no built-in exploration mechanism for online fine-tuning.
- Noise-space RL (DSRL
). Freeze the flow policy and run RL in noise space, learning to sample the optimal noise $X_0$ that generates high-reward actions. - Pro: bypasses BPTT cleanly without touching the flow policy at all; the multi-step structure is preserved as-is.
- Con: the policy’s action distribution is constrained to whatever the frozen pretrained flow policy can already produce. If the optimal action is not in its support, no choice of $X_0$ will recover it.
- Residual RL
. Freeze the flow policy and learn an additive residual $\Delta a$ at the action level. - Pro: simple to plug on top of any pretrained flow policy; the residual is a small, easy-to-train head.
- Con: operates purely at the action-space level, ignoring the multi-step generative process that produced the action. The residual can shift the final output but cannot reshape the underlying generative dynamics.
- Architectural reparameterization (SAC Flow
). Reparameterize the velocity network into a stable sequence-model form, either a GRU-style recurrence or a specific attention-based structure, so that BPTT through the denoising chain is stable by design. - Pro: preserves the multi-step structure and allows the velocity field itself to be fine-tuned end-to-end.
- Con: forces the velocity network into one of these specific structural forms. Existing pretrained flow policies (e.g., the VLAs cited above) generally do not match them and cannot be reused as-is.
Each line of work buys around BPTT by giving something up: sacrificing exploration (FQL), restricting the search to noise space (DSRL), correcting only at the action level (residual), or constraining the model architecture (SAC Flow).
A more fundamental issue cuts across all four: none of these methods comes with any guarantee of converging to the optimal tilted distribution \(\pi^*_Q(a \mid s) \propto \pi_{\text{base}}(a \mid s)\, \exp\!\big(Q(s, a)\big),\) which is the policy that off-policy RL is implicitly trying to reach.
Addressing this gap calls for a framework that operates on the multi-step sampling dynamics directly without BPTT or architectural modifications to the velocity field, and that converges to the optimal tilted distribution.
That is exactly what stochastic optimal control (SOC) offers.
Q-Adjoint Matching (QAM) and its hidden weakness
A recent line of work bypasses BPTT entirely by reformulating fine-tuning as a stochastic optimal control (SOC) problem
The idea is this. SOC adds a perturbation \(u\) on top of the pretrained flow policy’s sampling dynamics, steering trajectories toward higher-reward regions of the action space without ever backpropagating through the multi-step chain.
Now let’s make this precise. A flow policy is originally a deterministic ODE, but SOC needs stochastic dynamics, so we first rewrite the ODE as an equivalent SDE that produces the same marginal distribution of \(X_\tau\) at every timestep \(\tau\), including the same terminal \(X_1 \sim \pi_{\text{base}}\) (the equivalence in distribution follows from the Fokker–Planck equation)
Here \(b(X_\tau, \tau)\) is the drift, the deterministic component that sets the overall direction in which the trajectory is pushed toward actions. The diffusion coefficient \(\sigma(\tau)\) is the stochastic counterpart, controlling how much noise the Brownian motion \(B_\tau\) injects into the trajectory.
SOC then adds the control \(u(X_\tau, \tau)\) on top of the drift, giving the controlled SDE, which describes the sampling dynamics once the control \(u\) is applied:
\[dX_\tau = \big[b(X_\tau, \tau) + \sigma(\tau)\, u(X_\tau, \tau)\big]\, d\tau + \sigma(\tau)\, dB_\tau.\]The added term \(\sigma(\tau)\, u(X_\tau, \tau)\) is what steers each step of the sampling process away from the pretrained trajectory.
SOC is the problem of finding the control \(u\) that solves
\[\min_u\;\mathbb{E}\!\left[\, \frac{1}{2}\!\int_0^1 \|u(X_\tau, \tau)\|^2 \, d\tau \;-\; g(X_1) \,\right] \quad \text{subject to the controlled SDE above,}\]where \(g(X_1)\) is called the terminal cost on the final action and \(\tfrac{1}{2}\!\int_0^1 \|u(X_\tau, \tau)\|^2 d\tau\) is called the quadratic cost on the control. The terminal \(-g(X_1)\) encourages the trajectory to land at final actions \(X_1\) where \(g\) is large, and the quadratic cost penalizes the magnitude of \(u\). As we will see later, this quadratic cost is also what controls how far the sampling process deviates from the pretrained one, although the connection is not immediately apparent from the equation. The optimum is the smallest control magnitude that still achieves high terminal reward.
Adjoint Matching
Concretely, Adjoint Matching avoids BPTT by distributing the action-level cost gradient backward across intermediate timesteps via a lean adjoint ODE:
\[\tilde{a}_{\tau-h} = \tilde{a}_\tau + h\,\tilde{a}_\tau^\top \nabla_x\!\left(2 v^{\text{base}}(X_\tau, \tau) - \frac{1}{\tau}X_\tau\right), \quad \tilde{a}_1 = -\nabla_{X_1} g(X_1).\]The terminal condition \(\tilde{a}_1 = -\nabla_{X_1} g(X_1)\) is the cost’s gradient at the final action \(X_1\). The lean adjoint ODE then propagates this signal backward in time, giving \(\tilde{a}_\tau\) at each intermediate \(\tau\): the action-level cost signal, transported back to time \(\tau\). Crucially, \(\tilde{a}_\tau\) depends only on the pretrained \(v^{\text{base}}\) and the sampled trajectory, so it is \(\theta\)-independent.
With \(\tilde{a}_\tau\) in hand, the fine-tuned velocity field \(v_\theta^{\text{ft}}\) is then trained by minimizing the adjoint matching loss:
\[\mathcal{L}_{\text{Adj-Match}}(\theta) = \sum_\tau \left\| \tfrac{2}{\sigma(\tau)}\big(v_\theta^{\text{ft}}(X_\tau, \tau) - v^{\text{base}}(X_\tau, \tau)\big) + \sigma(\tau)\, \tilde{a}_\tau \right\|^2,\]where \(v_\theta^{\text{ft}}\)’s deviation from the pretrained \(v^{\text{base}}\) parameterizes the control \(u\). The loss is minimized when this deviation aligns with the transported signal \(\tilde{a}_\tau\) at every timestep. Taking \(\nabla_\theta \mathcal{L}_{\text{Adj-Match}}\) only differentiates through \(v_\theta^{\text{ft}}\) at each \(\tau\) individually, never through the multi-step forward chain. This is what makes the BPTT problem disappear (for the full derivation and further details, we refer to the original Adjoint Matching paper
Q-learning with Adjoint Matching (QAM)
So far so good. But both QAM and QAM-E inherit a more subtle problem: critic-induced instability.
In off-policy RL, the learned critic \(Q^\pi\) is inevitably imperfect: TD bootstrapping compounds approximation errors and tends to overestimate values
QAM’s terminal policy is exactly of this form, so any critic error inherits this exponential amplification directly.
This is not just a theoretical curiosity. The QAM paper itself recognized this fragility and applied gradient clipping as a partial remedy, but empirically that turns out to be insufficient. On Robomimic

On Robomimic-can, QAM and QAM-E start above 80% success but collapse to near zero as the adjoint loss diverges past \(10^{20}\) (right). TRQAM, in contrast, keeps both the success rate high and the adjoint loss stable throughout training. Shaded regions denote \(\pm 1\) standard deviation across seeds for success rate, and min–max across seeds for the adjoint loss.
The takeaway is this: the inverse temperature \(\beta\) controls a fundamental tradeoff between exploiting the critic and protecting against its errors. Large \(\beta\) exploits aggressively but can exponentially amplify critic errors (Lemma 1). Small \(\beta\) stays close to the pretrained policy and is safer, but throws away useful improvement signal. No single fixed \(\beta\) can handle both regimes, so we need to adapt it during training.
Trust Region Q-Adjoint Matching (TRQAM)
In on-policy RL, PPO
We borrow the same principle, but applying it to flow policies is non-trivial. Unlike a Gaussian policy whose actions are produced in a single step, a flow policy emerges from a multi-step sampling process. A trust region defined only on the terminal action distribution would leave the intermediate sampling process unconstrained. The constraint is more naturally imposed at the level of the sampling process itself.
This is the core idea of our method, Trust Region Q-Adjoint Matching (TRQAM). But how do we make this trust region concrete? In what follows, we show that the whole trust-region problem reduces to controlling a single scalar \(\lambda\), which we then adapt during training to enforce a target KL budget.
\(\lambda\) as a controllable trust region: an exact path-space KL identity
Following the SOC parameterization of SOCM
The product \(\sqrt{\lambda}\,\sigma(\tau) = \sqrt{2(1-\tau)/\tau}\) remains the memoryless OT schedule from Adjoint Matching, so \(\sigma(\tau)\) scales inversely with \(\sqrt{\lambda}\).
QAM itself does not introduce this \(\lambda\) scaling. Its diffusion coefficient is simply \(\sigma(\tau) = \sqrt{2(1-\tau)/\tau}\), with no separate scalar pulled out. Setting \(\lambda = 1\) in our framework therefore recovers QAM exactly.
Under this parameterization, we prove (Theorem 1, via Girsanov’s theorem) that the path-space KL between the trajectory distribution of the controlled SDE, \(\mathbb{P}^u\), and that of the base SDE, \(\mathbb{P}^{\text{base}}\), admits an exact closed-form expression in \(\lambda\):
\[D_{\text{KL}}(\mathbb P^u \,\|\, \mathbb P^{\text{base}}) \;=\; \mathbb{E}_{X \sim \mathbb P^u}\!\left[\frac{1}{2\lambda} \int_0^1 \|u(X_\tau, \tau)\|^2\, d\tau\right].\]Combining this with Proposition 1 (path-space KL upper-bounds the terminal KL) and Lemma 1 (critic-error amplification scales like \(\beta\varepsilon\)) gives the chain:
\[\frac{1}{\lambda} \;\overset{\text{Thm 1}}{\propto}\; \underbrace{D_{\text{KL}}(\mathbb P^u \| \mathbb P^{\text{base}})}_{\text{path-space KL}} \;\overset{\text{Prop 1}}{\ge}\; \underbrace{D_{\text{KL}}(\pi_\theta \| \pi_{\text{base}})}_{\text{terminal KL}} \;\overset{\text{Lem 1}}{\lesssim}\; \underbrace{\beta\varepsilon}_{\text{critic-error bound}}.\]While we refer to the paper for the detailed proofs, the intuitive takeaway is that controlling \(\lambda\) directly controls the terminal KL between the fine-tuned policy \(\pi_\theta\) and the pretrained base policy \(\pi_{\text{base}}\): \(\lambda\) effectively acts as the inverse of \(\beta\), so large \(\lambda\) behaves like a small \(\beta\) (conservative, safe from critic noise) and small \(\lambda\) like a large \(\beta\) (aggressive exploitation). Tuning \(\lambda\) therefore tunes the trust region directly.
Adapting \(\lambda\) via dual descent
To adapt \(\lambda\), we need two pieces: an estimator for the realized path-space KL, and a rule for updating \(\lambda\).
KL estimator. We discretize the controlled and base SDEs via the Euler scheme with step size \(h\). At each timestep \(\tau\), the one-step transitions of both SDEs are Gaussians sharing the same covariance \(h\, g(\tau)^2\, I\) (with \(g(\tau) := \sqrt{2(1-\tau)/\tau}\) the memoryless OT schedule), since they share the same diffusion coefficient. The KL between two such Gaussians has a closed form, and summing across timesteps gives a closed-form estimator of the path-space KL:
\[\hat{D}_n \;=\; \mathbb{E}_{X \sim \mathbb{P}^u}\!\left[\, \sum_{\tau \in \{0, h, \ldots, 1-h\}} \frac{2h}{g(\tau)^2}\,\big\|v_\theta^{\text{ft}}(X_\tau, \tau) - v^{\text{base}}(X_\tau, \tau)\big\|^2 \,\right].\]To reduce variance, we smooth \(\hat{D}_n\) with an exponential moving average, \(\bar{D}_n \leftarrow (1-\rho)\bar{D}_{n-1} + \rho\,\hat{D}_n\).
\(\lambda\) update. With \(\bar D_n\) as an estimate of the realized path-space KL, we now need a rule for adjusting \(\lambda\) to keep this KL near the target budget \(\varepsilon_{\text{KL}}\). The rule we use is projected dual descent: we view \(\lambda\) as the dual variable of the KL-constrained improvement problem
\[\max_u \mathbb{E}[Q^\pi(X_1)] \quad \text{s.t.} \quad D_{\text{KL}}(\mathbb P^u \| \mathbb P^{\text{base}}) \le \varepsilon_{\text{KL}},\]and update \(\lambda\) by dual descent (full derivation in the paper):
\[\lambda_{n+1} \leftarrow \max\!\big\{0,\; \lambda_n + \eta_\lambda (\bar D_n - \varepsilon_{\text{KL}})\big\}.\]The resulting mechanism is intuitive: \(\lambda\) acts as a feedback controller on the realized KL. When the trajectory drifts too far from the base (\(\bar D_n > \varepsilon_{\text{KL}}\)), \(\lambda\) rises and the controlled SDE pulls back toward the base; when it stays too close (\(\bar D_n < \varepsilon_{\text{KL}}\)), \(\lambda\) relaxes and allows more aggressive improvement.
Require: v_base, training step N 1: Init v_θ ← v_base, λ = 1 2: for n = 0, …, N−1 do 3: Sample X via SDE with v_θ, λ 4: Solve adjoint ODE 5: θ ← θ − ∇_θ L_AdjMatch (using σ) 6: 7: 8: end for
Require: v_base, training step N, KL budget ε_KL 1: Init v_θ ← v_base, λ_0, D̄_0, dual stepsize η_λ 2: for n = 0, …, N−1 do 3: Sample X via SDE with v_θ, λ_n 4: Solve adjoint ODE 5: θ ← θ − ∇_θ L_AdjMatch (using σ_n) 6: Estimate path-space KL along X; update EMA D̄_n 7: λ_{n+1} ← max{0, λ_n + η_λ(D̄_n − ε_KL)} 8: end for
Only the orange lines differ between QAM and TRQAM. QAM samples with a fixed \(\lambda\). TRQAM treats \(\lambda\) as the dual variable of a path-space KL constraint, estimates the realized KL along the trajectory, and updates \(\lambda\) via projected dual descent so that the trust-region budget \(\varepsilon_{\mathrm{KL}}\) is tracked throughout training.
Why internalizing \(\lambda\) matters
A natural alternative is to control the KL through a penalty term in the training loss, rather than letting \(\lambda\) reshape the SDE itself. We compare the two side by side:
\[\underbrace{\min_\theta\; \mathcal{L}_{\text{Adj-Match}}(\theta) + \lambda \cdot D_n(\theta)}_{\text{external: } \lambda \text{ as a loss-level penalty}} \quad\text{vs.}\quad \underbrace{\min_\theta\; \mathcal{L}_{\text{Adj-Match}}(\theta), \;\; \text{SDE uses } \sqrt{\lambda}\,\sigma(\tau)}_{\text{internal (TRQAM): } \lambda \text{ in the sampling SDE}}.\]The external form makes \(\lambda\) compete with critic guidance at the loss level, so under strong critic signals the realized KL drifts far beyond the budget. The internal form, by contrast, reshapes the entire controlled SDE. Since \(\sigma(\tau) \propto 1/\sqrt{\lambda}\), increasing \(\lambda\) shrinks \(\sigma(\tau)\), which directly weakens the control contribution \(\sigma(\tau)\, u(X_\tau, \tau)\) to the drift and pulls the SDE toward the base dynamics. By Theorem 1, the realized KL is then an exact function of \(\lambda\), so the dual update enforces the trust region structurally, not softly.
This distinction is reflected in training dynamics. With external KL regularization, the realized KL drifts well above the target budget, and the task success rate degrades as the KL grows. TRQAM, by contrast, tracks the target \(\varepsilon_{\text{KL}}\) tightly throughout training and maintains a stable success rate.

Internal KL (TRQAM) tracks the prescribed target \(\varepsilon_{\mathrm{KL}} = 0.1\) tightly throughout training on both Robomimic-lift and Robomimic-can. External KL regularization lets the realized KL drift well above the target, and the success rate degrades as the KL grows. Shaded regions denote \(\pm 1\) standard deviation across seeds.
Results
On 50 OGBench
| Method | al | ag | hm | hl | scene | p33 | p44 | c2 | c3 | c4 | all | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 5 tasks | 5 tasks | 5 tasks | 5 tasks | 5 tasks | 5 tasks | 5 tasks | 5 tasks | 5 tasks | 5 tasks | 50 tasks | ||
| Backprop | FQL | 38±9 | 2±6 | 74±5 | 2±1 | 70±5 | 25±10 | 9±7 | 44±4 | 7±5 | 9±5 | 28 |
| Guidance | CGQL-L | 48±7 | 7±5 | 57±2 | 6±3 | 58±1 | 0±0 | 0±0 | 55±2 | 0±1 | 1±1 | 23 |
| Post Processing | DSRL | 53±2 | 1±1 | 53±10 | 1±1 | 80±0 | 100±0 | 61±8 | 72±4 | 34±6 | 9±3 | 46 |
| IFQL | 29±8 | 12±3 | 93±2 | 30±7 | 36±1 | 64±4 | 42±4 | 9±2 | 24±7 | 6±3 | 35 | |
| Adjoint Matching | QAM | 62±9 | 29±4 | 64±7 | 4±3 | 64±4 | 15±3 | 1±1 | 71±2 | 19±6 | 18±3 | 35 |
| QAM-E | 86±3 | 6±8 | 60±6 | 4±5 | 63±6 | 89±4 | 54±8 | 71±3 | 11±4 | 9±3 | 45 | |
| Ours | TRQAM | 89±4 | 41±4 | 84±3 | 36±4 | 79±1 | 100±0 | 99±1 | 81±3 | 50±5 | 19±5 | 68 |
Offline RL on 50 OGBench tasks at 1M training steps (8 seeds). Mean success rate (%) with ±1 standard deviation. Domain abbreviations: al = antmaze-large, ag = antmaze-giant, hm = humanoidmaze-medium, hl = humanoidmaze-large, p33 = puzzle-3x3, p44 = puzzle-4x4, c2 = cube-double, c3 = cube-triple, c4 = cube-quadruple. Gray cells mark the best baseline per column; TRQAM (orange) reaches 68% overall against 46% for the strongest baseline.
Sensitivity analysis
We have so far argued that \(\varepsilon_{\text{KL}}\) is a trust-region budget for the path-space KL. To check that this label is more than cosmetic, we vary \(\varepsilon_{\text{KL}}\) and ask whether the policy responds in a predictable, controlled way.
Sweeping \(\varepsilon_{\text{KL}} \in \{0.5, 1, 1.5, 2, 2.5, 3, 3.5, 4\}\) on four representative OGBench tasks gives a clear answer:

Sensitivity to \(\varepsilon_{\text{KL}}\) on four OGBench tasks. White background is offline RL, orange background is online fine-tuning. Shaded regions denote \(\pm 1\) standard deviation across seeds.
- Smooth, ordered response. Success rate changes with \(\varepsilon_{\text{KL}}\) in a predictable way on every task: the ordering across budgets is largely preserved throughout training, and the curves do not jump erratically between neighboring budgets.
- Tight budgets are usually best. On all four tasks above, smaller \(\varepsilon_{\text{KL}}\) trains faster and reaches higher success. The notable exception is
puzzle-4x4, whose larger state space prefers a looser budget (Appendix H.3 of the paper). In other words, the optimum tracks task structure rather than being arbitrary.
Together, these patterns indicate that \(\varepsilon_{\text{KL}}\) behaves as a controlled axis rather than an arbitrary knob: its effect on training is smooth and ordered, and its optimum tracks task structure. In other words, the path-space KL bound is not just a theoretical artifact of the SOC derivation; it is an empirically meaningful axis along which trust-region fine-tuning can be reasoned about.
BibTeX
@article{dong2026trqam,
title = {Trust Region Q Adjoint Matching},
author = {Dong, Yonghoon and Lee, Kyungmin and Kim, Changyeon and Kim, Jaehyuk and Shin, Jinwoo},
journal = {arXiv preprint arXiv:2605.27079},
year = {2026}
}